
A medida que el panorama de las aplicaciones evoluciona, las empresas se encuentran en la necesidad de evaluar nuevas bases de datos que soporten los cambios y los nuevos requisitos de negocio. Analizamos algunos criterios claves para evaluar las bases de datos emergentes de tipo no relacional (NoSQL).
Las bases de datos relacionales tradicionales ocupan una posición muy destacada actualmente en las empresas. Respaldan las aplicaciones heredadas que cumplen con las necesidades del negocio, cuentan con una largo número de profesionales calificados para implementar y mantener sus sistemas y cuentan con un amplio y contrastado ecosistema de herramientas en el mercado.
Sin embargo, durante estos últimos años, las empresas también empiezan a considerar alternativas, como las bases de datos NoSQL, principalmente motivadas por las siguientes razones:
- Utilizar sistemas más económicos y menos complejos que reduzcan los costes licencias, infraestructura y desarrollo.
- Encontrar sistemas más escalables a los actuales, especialmente para servir datos en los que la importancia del contenido es baja y para aplicaciones que manejan Big Data.
- Utilizar modelos de datos más flexibles y reusables que los que ofrece el modelo relacional en sí mismo con las operaciones SQL.
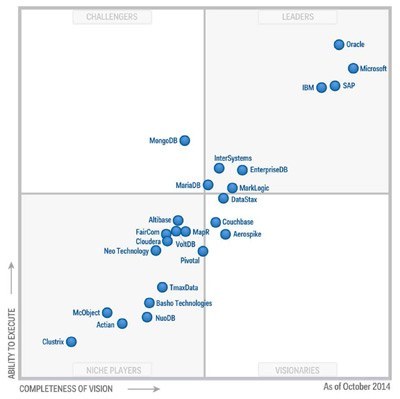
De este modo, el término NoSQL, o Not only SQL, representa una amplia clase de sistemas de gestión de bases no relacionales, distribuidas, horizontalmente escalables, de código abierto y, a priori más rápidas, ya que no implementan las propiedades ACID (Atomicity, Consistency, Isolation and Durability) que si presentan las bases de datos relacionales. Aunque esto último no siempre es cierto, ya que muchos de estos sistemas aún no son suficientemente maduros.
Modelo de datos
Una de las principales diferencias entre las bases de datos NoSQL y las bases de datos relacionales es el modelo de datos. Aunque actualmente existen alrededor de 150 tipos de bases de datos NoSQL distintas, sus modelos de datos pueden agruparse en tres grandes grupos:
| MODELO DE DATOS | FORMATO | CARACTERÍSTICAS | APLICACIONES |
|---|---|---|---|
| Documento | Similar a JSON (*JavaScript Object Notation*) | - Intuitivo - Manera natural de modelar datos cercana a la programación orientada a objetos - Flexibles, con esquemas dinámicos - Reducen la complejidad de acceso a los datos | Se pueden utilizar en diferentes tipos de aplicaciones debido a la flexibilidad que ofrecen |
| Grafo | Nodos con propiedades (atributos) y relaciones (aristas) | - Los datos se modelan como un conjunto de relaciones entre elementos específicos - Flexibles, atributos y longitud de registros variables - Permite consultas más amplias y jerárquicas | Redes sociales, software de recomendación, geolocalización, topologías de red ... |
| Clave-Valor y Columna | **Clave-valor:** una clave y su valor correspondiente **Columnas:** variante que permite más de un valor (columna) por clave | - Rendimiento muy alto - Alta curva de escalabilidad - Útil para representar datos no estructurados | Aplicaciones que solo utilizan consulta de datos por un solo valor de la clave |
Modelo de consultas
Cada aplicación tiene unos requisitos distintos. En algunos casos, es suficiente tener un modelo de consultas básico en el que la aplicación acceda a los registros basándose en una clave primaria. Sin embargo, en la mayoría de aplicaciones, es necesario poder ejecutar consultas basándose en varios valores distintos para cada uno de los registros.
- Bases de datos orientadas a documento: Este tipo de bases de datos proporcionan la posibilidad de ejecutar consultas en base a cualquier tipo de campo dentro del documento. Las bases de datos orientadas a documento también permiten hacer consultas basadas en índices secundarios. Esto permite actualizar registros incluyendo uno o más campos dentro del documento.
- Bases de datos orientadas a grafo: El almacenamiento en este tipo de bases de datos está optimizado para ejecutar la navegación entre nodos (traversals). Por este motivo, las bases de datos orientadas a grafo son eficientes para realizar consultas en las que existan relaciones de proximidad entre datos, y no para ejecutar consultas globales.
- Bases de datos clave-valor y orientadas a columna: Este tipo de sistemas permiten obtener y actualizar datos en base a una clave primaria. Las bases de datos clave-valor y orientadas a columna ofrecen un modelo de consultas limitado que puede imponer costes de desarrollo y requisitos a nivel de aplicación para ofrecer un modelo de consultas avanzado. Un ejemplo de esto son los índices, que deben ser gestionados por el propio usuario.

En los sistemas consistentes se garantiza que las escrituras sean inmediatamente visibles para las consultas posteriores. Este tipos de sistemas son especialmente útiles para aplicaciones en las que se hace indispensable que los datos sean siempre coherentes. Los sistemas consistentes proporcionan ventajas en las escrituras, aunque, por contra, las lecturas y las actualizaciones son más complejas.
En los sistemas eventualmente consistentes, un término popularizado por Amazon, existe un periodo durante el que no todas las copias de los datos están sincronizadas. El hecho de no tener que comprobar la consistencia de los datos en cada una de las operaciones supone una mejora importante en el rendimiento y disponibilidad del sistema, aunque para ello se sacrifique la coherencia de los datos. Estos tipos de sistemas son especialmente útiles para datos que no cambian a menudo, como archivos históricos o logs.
Las bases de datos orientadas a documento o grafo existentes pueden ser consistentes o eventualmente consistentes, mientras que las bases de datos clave-valor y orientadas a columna son típicamente eventualmente consistentes.
APIS
La principal funcionalidad de la API (Application Programming Interface) es mantener el diálogo con la base de datos, para poder llevar a cabo el acceso y manipulación de los datos.
Las bases de datos NoSQL no cuentan con un estándar, por lo que cada base de datos posee su propia API. La madurez de la API repercute tanto en el tiempo como en el coste del desarrollo de aplicaciones.
Algunos sistemas utilizan drivers idiomáticos que permiten trabajar con los datos y servicios utilizando los paradigmas de un lenguaje de programación concreto. Mediante este enfoque se aprovechan las características específicas del lenguaje de programación para acceder y procesar los datos de la manera eficiente. Para los programadores, los drivers idiomáticas son fáciles de aprender y reducen el tiempo de adaptación a un nuevo sistema de datos.
Otras bases de datos utilizan interfaces RESTful. Este enfoque es sencillo y conocido, pero tiene asociadas las latencias inherentes del protocolo HTTP.
Soporte comercial y de la comunidad
El soporte comercial y de la comunidad son puntos importantes que también se deben tener en cuenta para seleccionar una base de datos.
En cuanto al soporte comercial es importante evaluar tanto el estado del proyecto como de la empresa que lo respalda. No solo es importante la continuidad del producto, sino sus expectativas de evolución. Es importante que la empresa que lo respalde sea fuerte, cuente con experiencia y ofrezca servicios añadidos: soporte, consulting, training y certificaciones, herramientas de desarrollo …
Las ventajas de tener una comunidad fuerte en torno a una base de datos son las siguientes:
- Se facilita el encontrar profesionales que estén familiarizados con el producto.
- Ayuda a encontrar documentación, código y ejemplos más fácilmente.
- Impulsa a otras organizaciones y empresas a desarrollar integraciones y participar en el ecosistema.






